Protect your smartphone, cards, and car keys from tracking, skimming, and unwanted radio-frequency exposure. The pouch’s metal-textile material absorbs and blocks RF signals, including RFID, Wi-Fi, Bluetooth, GSM, 4G, 5G, GPS. When your phone is placed inside, it becomes unreachable for calls, location tracking, and data access. This bag ensures your privacy and offers extra protection for electronics during storms during for yachting, trekking, and outdoor activities. Crafted from high-quality materials and thoroughly tested for reliability. Delivery in EU.
The Intricate Tapestry of ChatGPT Texts: Why LLM overuses some words at the expense of others?
Ever wondered why ChatGPT texts are heavy on certaint words? This article talks about word frequencies in fake posts. We'll review some examples and introduce a vocabulary-based ChatGPT detector.
If you’ve been wondering why ChatGPT texts are heavy on certain words, you are surely not alone. There is a recent thread on Reddit didicated to OpenAI’s «intricate tapestry» phenomenon, as these are among word that you often see across prompts. An anecdotal vocabulary of ChatGPT’s favourites also includes the words «intricacy», «vibrant», «breathtaking», «innovative», and so on. ChatGPT would write about «catering» to the needs of clients, making something «seamless» and suggesting «a no hassle solution»… As we shall see below, there is also a remarkable place for the «t-word» in ChatGPT’s reply to prompts. «Tapestry», yes, we are getting there.
In the vibrant, dynamic, multifaceted, kaleidoscopic and multidimensional world of AI, one linguistic generator program stood out from the rest: ChatGPT. A testament to its algorithm, the program sought to weave intricate threads of information to create a rich tapestry of knowledge. Redit User
You can download data in this post by cloning chatgpt_corpus.
In the world of AI generated texts there is a big issue: spam that originates from ChatGPT and other LLMs. Generally speaking, that is the problem of automated detection of potentially useless texts that were generated by LLMs. In this post, I would like to share some of my findings from a collection of about 2K texts created by ChatGPT. We’ll take into consideration certain lexicographical features that are evident if you compare AI texts with human ones.
You can view the ChatGPT collection in semascope viewer, which shows graphically how words relate to each other: here.
Collecting data
Discovering a website that contained large amount of generated content turned our an easy task. It was as simple as typing a search query, «collection of AI-generated texts». And that is exactly how I found a web page titled «Smarhon: A Journey into Belarus’ Untouched Cultural Heritage». It screams, ‘ChatGPT wrote me’, and you will appreciate if I show you a sample:
As you wander through the charming streets of Smarhon, make sure to marvel at its architectural treasures. The Church of St. Michael the Archangel, built in the 18th century, stands as a symbol of the town’s religious heritage. Its stunning frescoes and intricate wood carvings are a sight to behold. Another architectural gem is the Smarhon Castle, which dates back to the 17th century. Once a powerful fortress, it now houses a museum that offers a glimpse into the town’s past. Explore its exhibition halls, which display artifacts highlighting Smarhon’s historical significance. Immersing in Nature’s Beauty…
There are many thousand posts like this, they literally go without end. I found myself looking at sitemap.xml of the site. Reading into the urls clearly suggests that the posts are iterations of machine-written and rewritten text, all over and over again. A kind of fake promo info about a traveling destination.
Once the sitemap.xml file is downloaded, we can create a list of URLs and pass it over to wget:
The –reject option is used to exclude certain file types (images, CSS, and JS files) as we only need texts.
Preparing text files
In a few hours, not without impatience, I got a collection of about 2000 posts from the «Smarhon» website. I went on to parse html into pure txt, as the layout contained actual posts (whithout the navigation elements) inside <p> tags.
Here is the Python script that was used for parsing:
import os
from bs4 import BeautifulSoup
def extract_text_from_html(html_content):
soup = BeautifulSoup(html_content, 'html.parser')
paragraphs = soup.find_all('p')
return '\n'.join(paragraph.get_text(separator='\n') for paragraph in paragraphs)
def process_html_files(directory):
file_counter = 111 # Starting number for output files
for filename in os.listdir(directory):
input_path = os.path.join(directory, filename)
output_path = os.path.join(directory, f'{file_counter}.txt')
with open(input_path, 'r', encoding='utf-8') as file:
html_content = file.read()
extracted_text = extract_text_from_html(html_content)
with open(output_path, 'w', encoding='utf-8') as output_file:
output_file.write(extracted_text)
print(f"Processed: {input_path} -> {output_path}")
file_counter += 1
if __name__ == "__main__":
# Set HTML files directory here:
html_directory = '/local-directory'
process_html_files(html_directory)
Now we have the posts as clean txt files, although some additional parsing is required to get rid of noise. An inspection of parsed data suggested that some pages were in German, while most of them in English. What should we do? First I also gut stuck with the problem, because there is no way I was going to check every file manually.
A good thing is that we can use Python to check each text for its language - and you can do it automatically! Firstly, install the needed module, it is called langdetect:
pip install langdetect
Well done. And here is the script to do language detection, comments are to give you a clue of what’s going on.
import os
from langdetect import detect
def detect_language(text):
try:
language = detect(text)
return language
except:
return "Unknown"
def process_txt_files(directory):
for filename in os.listdir(directory):
if filename.endswith('.txt'):
input_path = os.path.join(directory, filename)
# Read the content of the file
with open(input_path, 'r', encoding='utf-8') as file:
content = file.read()
# Detect the language of the content
language = detect_language(content)
if language == "en":
# If the detected language is English, rename the file
new_filename = f'EN-{filename}'
output_path = os.path.join(directory, new_filename)
os.rename(input_path, output_path)
print(f"Renamed: {input_path} -> {output_path}")
else:
print(f"Ignored: {input_path} (Language: {language})")
if __name__ == "__main__":
txt_directory = '/local-directory'
process_txt_files(txt_directory)
Please, do not call the script language.py as such a name will interfere with the module. I called the script langdetect.py and ran it by doing python3 langdetect.py from the Linux console. All worked surprisingly fast, the script properly inspected the data, and upon a brief checkup I moved files starting with EN- to a separate folder:
cp ./local-directory/EN* ./local-directory/EN/
The preparation part is almost over, so read on.
Building frequency list for AI-generated corpus
Now we have a small corpus of AI-generated texts that we took from what seems to be a SEO spam website with many thousands of ChatGPT junk posts. You can download it here.
And now, finally, we can start with our data mining, namely with a corpus-linguistical analysis. Our research questions are as follows:
Which words are underrepresented in the ChatGPT corpus?
What lexis is overrepresented in AI-generated texts?
Can we distinguish between actual human texts and ChatGPT prompts? What is the difference?
Such questions are many, and they can only be answered when you have sufficient data, so let’s try playing around with the LLM spam corpus of 1.2 mln words.
A few notes on the text file we are going to analyze. Each line contains a separate web article, so there are as many posts as there are lines in the file, exactly N=1922 shitposts. Texts do not repeat each other literally.
So, the big text file with all GPT posts is prepared, let’s see how many tokens are there:
A wordlist is a frequency list, where words are listed with the most frequent coming first, descending to the least frequent. But such data alone is often useless: instead, we need to calculate probability of meeting the word in our little corpus, a collection of SEO spam documents. For this purpose we can take tokens, the number of individual words in the text, and calculate relative freqency of each word, i.e. ratio of word frequency to total number of words.
There is a number of word rank lists, or word frequency vocabularies, for different languages, and you can get this data from the web. Wikipedia is a good starting point to get it. To compare how probable we are to find a word in AI-generated texts against natural texts, I chose the list from Project Gutenberg books. It is dated back to 2006, way before AI-generated texts flooded the web, so we can safely assume that the texts are «pure human». This is what Wikipedia writes about the list: «These lists are the most frequent words, when performing a simple, straight (obvious) frequency count of all the books found on Project Gutenberg».
The PG list that we are going to use contains top 40000 English words as seen in all Project Gutenberg books in April 2006, good enough for our purpose. The PG list includes word frequency in the format of ‘per billion’, fractions are limited to two decimal places and the words are case insensitive.
Let us now extract data from our ChatGPT corpus, using the same format as in the Project Gutenberg list:
import re
import csv
from collections import Counter
def calculate_word_frequency(file_path, output_path):
# Read the content of the file
with open(file_path, 'r', encoding='utf-8') as file:
text = file.read()
# Tokenize the text using a simple regex
tokens = re.findall(r'\b\w+\b', text.lower())
# Calculate word frequencies
word_frequencies = Counter(tokens)
# Total number of tokens
total_tokens = len(tokens)
# Calculate frequency per actual tokens and induced frequency per billion tokens
result = []
for word, frequency in word_frequencies.items():
frequency_per_token = frequency / total_tokens
frequency_per_billion_tokens = frequency_per_token * 1e9
result.append((word, frequency, frequency_per_token, frequency_per_billion_tokens))
# Sort the result by frequency in descending order
result.sort(key=lambda x: x[1], reverse=True)
# Write the result to a CSV file
with open(output_path, 'w', newline='', encoding='utf-8') as csvfile:
fieldnames = ['Word', 'Frequency', 'Frequency per Token', 'Frequency per Billion Tokens']
writer = csv.DictWriter(csvfile, fieldnames=fieldnames)
# Write the header
writer.writeheader()
# Write each row
for word, frequency, freq_per_token, freq_per_billion in result:
writer.writerow({
'Word': word,
'Frequency': frequency,
'Frequency per Token': freq_per_token,
'Frequency per Billion Tokens': freq_per_billion
}) # Example usage: replace 'your_file.txt' and 'results.csv' with the actual file paths
calculate_word_frequency('/local-folder/EN/chat-gpt-EN.txt', 'gpt-results.csv')
The resulting file, gpt-results.csv, contains a ChatGPT word frequency list according to about 2000 texts that were harvested on the web, although it was taken from just one particular website. This is the way, however, to expand the ChatGPT corpus by adding new AI-generated texts, should anyone want to do that.
Next stage, we need to merge the PG word frequency list and our vocabulary file, gpt-results.csv.
You can do that by executing the following UNIX one-liner, so wait no more and go back to your command line prompt:
$ awk -F',' 'NR==FNR{a[$1]=$0; next} $1 in a {print a[$1] "," $0}' <(sort PGrank.csv) <(sort gpt-results.csv) > CompareRanksGPTvsPG.csv
On a side note, wk -F',' means, ‘use comma as a field separator’. The idea is, firstly, sort the two lists that we are going to merge. And take only words that exist in both lists and keep corresponding word frequency statistics from the original two files.
The datafile that I got (and you can download it later) looks like this:
Word
Frequency per Billion 1
Word
Frequency
Frequency per Token
Frequency per Billion 2
Ratio
www
39.5567
www
4033
0.00292420133702635
2924201.33702635
1.35273517247706E-05
breathtaking
18.196
breathtaking
910
0.000659812352267289
659812.352267289
2.75775376703297E-05
belarusian
41.9301
belarusian
1548
0.00112240606737337
1122406.06737337
3.73573354767441E-05
iconic
12.6581
iconic
301
0.000218245624211488
218245.624211488
5.79993300930232E-05
belarus
211.232
belarus
4716
0.0034194231354863
3419423.1354863
6.1774162374894E-05
cinematic
7.91134
cinematic
171
0.000123986716744732
123986.716744732
6.38079643345031E-05
effortlessly
40.3478
effortlessly
625
0.000453167824359402
453167.824359402
0.0000890350060864
innovative
87.8159
innovative
1311
0.000950564828376282
950564.828376282
9.23828626712433E-05
customize
13.4492
customize
167
0.000121086442668832
121086.442668832
0.000111071063808383
gamer
26.1074
gamer
298
0.000216070418654563
216070.418654563
0.000120828201114094
upcoming
54.5882
upcoming
533
0.000386461520613698
386461.520613698
0.000141251320217636
showcase
101.265
showcase
863
0.000625734131875462
625734.131875462
0.00016183390811124
unleash
71.9932
unleash
520
0.000377035629867022
377035.629867022
0.000190945349184616
maximize
57.7528
maximize
417
0.000302353572412593
302353.572412593
0.000191010807443645
blockbuster
8.70248
blockbuster
61
4.42291796574776E-05
44229.1796574776
0.000196758792891803
options
329.903
options
2039
0.00147841471019011
1478414.71019011
0.000223146453918588
hassle
37.1833
hassle
223
0.000161690279731435
161690.279731435
0.000229966204905829
immerse
346.516
immerse
2004
0.00145303731202599
1453037.31202599
0.000238477014411177
powered
116.296
powered
665
0.000482170565118404
482170.565118404
0.00024119265756391
optimize
29.2719
optimize
152
0.000110210414884207
110210.414884207
0.000265600125276315
informative
117.087
informative
596
0.000432140837309126
432140.837309126
0.000270946390369127
… and so on. There are 4604 words in it, each attested at lest once in the ChatGPT corpus. That is slightly over 10 per cent of the top 40000 common English words from Project Gutenberg books!.
Frequency per Billion 1 is the Project Gutenberg probability to find the word, and Frequency per Billion 2 is same for our 2K posts ChatGPT corpus. Ratio is Frequency per Billion 1 divided by Frequency per Billion 2. I calculated it as a measure of how many times the word in the ChatGPT word list overused in comparison to the Project Gutenberg word frequency. The table is sorted by this ratio, so you can immediately recognize some of ChatGPT’s favourites, including the words ‘breathtaking’, ‘effortlessly’, ‘innovative’, ‘showcase’, ‘immerse’. So far, very ‘informative’ and ‘no hassle’!
Tapestry is seriously overused by ChatGPT
Attention, now we come to the big fun part!
How about the word ‘tapestry’? Is it really used so often in ChatGPT posts? The answer: It turns out, in a text sample of about 2000 texts that were generated by ChatGPT, the word ‘tapestry’ is used at the rate of 102959 words per billion, whereas in the Project Gutenberg corpus the same word is 25 times less common (occurs at 4099.65 words per billion).
Here are some more examples of English words overused by ChatGPT:
Word
Frequency per Billion 1
Word
Frequency
Frequency per Token
Frequency per Billion 2
Ratio
tapestry
4099.65
tapestry
142
0.000102959729694456
102959.729694456
0.0398179949788733
intricate
5167.69
intricate
824
0.000597456459635436
597456.459635436
0.00864948385218446
vibrant
1134.48
vibrant
1972
0.00142983511941879
1429835.11941879
0.000793434141176468
extravaganza
160.6
extravaganza
2
1.45013703795009E-06
1450.13703795009
0.110748154
gem
4187.47
gem
2018
0.00146318827129164
1463188.27129164
0.00286188051268582
unleash
71.9932
unleash
520
0.000377035629867022
377035.629867022
0.000190945349184616
unlock
1503.15
unlock
859
0.000622833857799562
622833.857799562
0.002413404443539
streamline
51.4237
streamline
23
1.6676575936426E-05
16676.575936426
0.00308358863330435
blend
2933.52
blend
1062
0.000770022767151496
770022.767151496
0.00380965359096045
colorful
329.111
colorful
124
8.99084963529053E-05
89908.4963529054
0.00366051055629032
testament
2316.44
testament
730
0.000529300018851782
529300.018851782
0.00437642153315068
The situation gets even more dramatic with some notorious words from the ‘Reddit Lexicon of ChatGPT’. Here are a few examples from the data. The word ‘intricate’ was used 115x more often in ChatGPT sample of texts when compared to Project Gutenberg books, ‘vibrant’ - a shocking 1260x times increase. ‘Extravaganza’ - a 25x overuse. The award goes to ‘breathtaking’. In the sample data it is the top words overused by GPT. It has the rate of 659812 words per billion in ChatGPT texts, that is 36261 times more than in texts written by us, humans. ‘Testament’ is 228 times more frequent in GTP texts, ‘landscape’ - 10 times, and so on, see full data in the repo files.
What you read in this post is implemented as a vocabulary-based ChatGPT detector. You can try the ChatGPT Detector here
Words systematically underused by ChatGPT
Let us further ‘dwell into the intricacies’ of ChatGPT lingo. Our sample of AI-written texts reveal an interesting list of underused words. These are words that happen unnaturally rare in ChatGPT posts when compared to the corpus of Project Gutenberg books.
This table lists words that occur in ChatGPT posts with the probability of at least 200x less when compared to same words in Project Gutenberg corpus:
Word
Frequency per Billion 1
Word
Frequency
Frequency per Token
Frequency per Billion 2
Ratio
copyright
145244
copyright
1
7.2506851897504E-07
725.068518975043
200.31761992
round
291647
round
2
1.45013703795009E-06
1450.13703795009
201.116854729999
certain
296795
certain
2
1.45013703795009E-06
1450.13703795009
204.666864049999
low
149690
low
1
7.2506851897504E-07
725.068518975043
206.4494542
six
151612
six
1
7.2506851897504E-07
725.068518975043
209.10023816
cut
152625
cut
1
7.2506851897504E-07
725.068518975043
210.4973475
nearly
154001
nearly
1
7.2506851897504E-07
725.068518975043
212.39509918
none
155743
none
1
7.2506851897504E-07
725.068518975043
214.79763074
south
158664
south
1
7.2506851897504E-07
725.068518975043
218.82621552
purpose
162154
purpose
1
7.2506851897504E-07
725.068518975043
223.63955372
began
325327
began
2
1.45013703795009E-06
1450.13703795009
224.342245929999
turned
337367
turned
2
1.45013703795009E-06
1450.13703795009
232.644909529999
continued
169086
continued
1
7.2506851897504E-07
725.068518975043
233.20002948
door
342388
door
2
1.45013703795009E-06
1450.13703795009
236.107340919999
god
552668
god
3
2.17520555692513E-06
2175.20555692513
254.076217413333
enough
382266
enough
2
1.45013703795009E-06
1450.13703795009
263.606810939999
course
385303
course
2
1.45013703795009E-06
1450.13703795009
265.701095769999
could
1571110
could
8
5.80054815180035E-06
5800.54815180035
270.855436225
french
199969
french
1
7.2506851897504E-07
725.068518975043
275.79324542
mean
211299
mean
1
7.2506851897504E-07
725.068518975043
291.41935482
really
211722
really
1
7.2506851897504E-07
725.068518975043
292.00274796
earth
222546
earth
1
7.2506851897504E-07
725.068518975043
306.93099228
reason
229940
reason
1
7.2506851897504E-07
725.068518975043
317.1286492
because
465587
because
2
1.45013703795009E-06
1450.13703795009
321.064139329999
hour
237964
hour
1
7.2506851897504E-07
725.068518975043
328.19518952
fact
263613
fact
1
7.2506851897504E-07
725.068518975043
363.56977734
received
264606
received
1
7.2506851897504E-07
725.068518975043
364.93930308
person
267878
person
1
7.2506851897504E-07
725.068518975043
369.45198004
children
275607
children
1
7.2506851897504E-07
725.068518975043
380.11166226
till
304735
till
1
7.2506851897504E-07
725.068518975043
420.2844173
death
309653
death
1
7.2506851897504E-07
725.068518975043
427.06722454
man
1573117
man
5
3.62534259487522E-06
3625.34259487522
433.922300812
morning
330567
morning
1
7.2506851897504E-07
725.068518975043
455.91139506
had
6139336
had
17
1.23261648225757E-05
12326.1648225757
498.073495557648
did
1185720
did
3
2.17520555692513E-06
2175.20555692513
545.1071032
knew
413101
knew
1
7.2506851897504E-07
725.068518975043
569.74063718
very
1462382
very
3
2.17520555692513E-06
2175.20555692513
672.296002253333
my
3277699
my
4
2.90027407590017E-06
2900.27407590017
1130.134226705
i
11764797
i
11
7.97575370872548E-06
7975.75370872547
1475.07024786
his
8799755
his
8
5.80054815180035E-06
5800.54815180035
1517.0557626125
her
5202501
her
2
1.45013703795009E-06
1450.13703795009
3587.59266458999
said
2637136
said
1
7.2506851897504E-07
725.068518975043
3637.08522848
he
8397205
he
1
7.2506851897504E-07
725.068518975043
11581.2571919
The pronoun ‘he’ - over 11500 more frequent in natural texts when compared to ChatGPT replies, ‘her’ - about 3600 times, ‘reason’ - 317 times, ‘god’ - 254 times, ‘purpose’ - 223 times. One can expect that these words are not seen often in typical ChatGPT replies.
The word ‘woman’ was not seen in the ChatGPT sample at all. Surprisingly, the pronoun ‘she’, one of the most common words in the English language, was not attested neither. You can check this by downloading the data used in this post, to do that, clone chatgpt_corpus.
Are word frequencies in ChatGPT texts and in natural texts correlated?
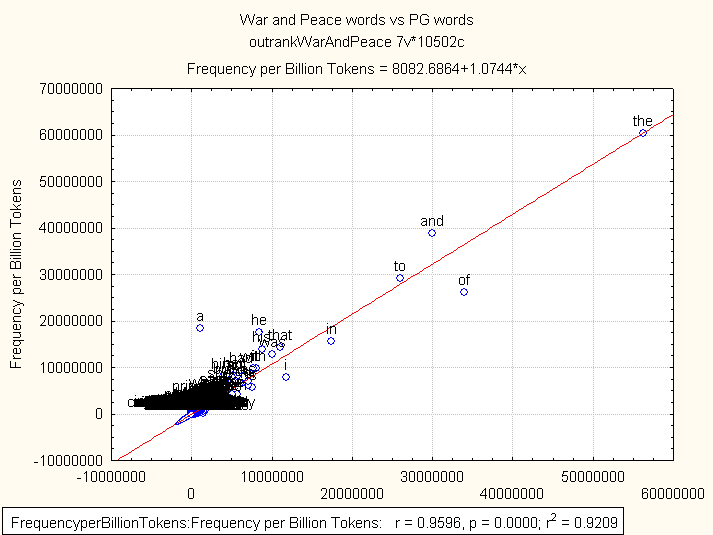
An important question about the quantitative nature of AI-generated texts is if rate of vocabulary use is at all realated to what we find in natural language. The short preliminary answer is, yes, but the correlation is not very strong. Firstly, a few words on the quality of Project Gutenberg word frequency list. It appears that the PG list from Wikipedia can be trusted, because if you compare word frequencies (per billion) in the PG list and in a comparatively large human text, the values are strongly correlated. Using same script as in «Python script to create word frequency lists» above, I gathered statistics from Tolstoy’s War and Peace, and compared the Frequency per Billion 1 with Frequency per Billion 2 columns. The first one is from PG list, while the second was induced from War and Peace. Here is the result: Pearson r is very strong, 0.96 with a highly significant p-value < 0.00001.
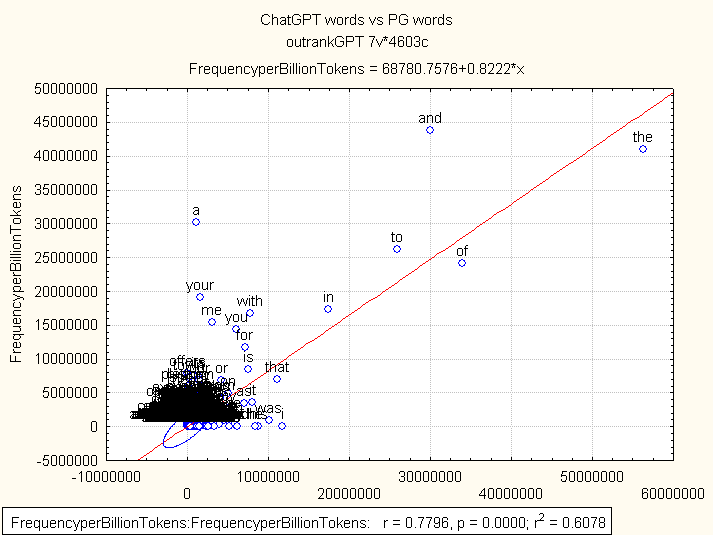
ChatGPT vocabulary, compared with the PG list. Pearson’s correlation was r=0.078 with p < 0.00001. Seems strong. But if you look at the scatter plot below, you can see that there is a handsome of outliers, namely the most common English words, ‘the’, ‘and’, ‘to’, ‘of’. They make an impact on the statistic. These words are apparently more or less at the same rate of occurrence in both lists (we are comparing ChatGPT words and the Project Gutenberg list). For example, ‘the’ shows at 56271872 words per billion in PG and 40964921 in the ChatGPT sample. Well, that is at least at the same order. ‘And’ plus a few other function words exhibit same properties in the AI-generated sample of 1,325 mln tokens that we gathered in the web.
ChatGPT samples compared with Project Gutenberg frequency list
War and Peace compared with Project Gutenberg frequency list
Finally, let’s see some descriptive statistics for word lists. In War and Peace, when compared against the PG list, expected word frequency vs observed (that ratio we were previously talking about) has the mean of 1.82 and the median of about 0.97. It means, half of words in War and Peace that are also among 40 000 most frequent in English, show same probability of occurrence. That can not be said of the GPT corpus. In the AI-generated sample, the mean is 17.25 and the median is 1.64. Descriptive data for ChatGPT texts, when compared to Project Gutenberg data, suggests that AI-generated texts are fundamentally different from human writings.
You should now be wondering, what exactly is the difference between ChatGPT texts and in natural data? We’ll continue investigating this question in the next post. I will show that the differnce deals with the distribution of word frequencies. A preliminary analysis of textual data indicates that ChatGPT avoids word aggregation, or ‘burstiness’, so common in natural language. So, please, read about it in the next post.
Oh, since you’ve finally got here: What does ChatGPT has to say about the «intricate tapestry» phenomenon? I presented the results of our research to ChatGPT to see their replies and explanations. Here is what I learned from a few prompts - read in the next post!